Barbell Speed Tracking
A Computer Vision Investigation
Velocity-based training uses barbell speed as a real-time proxy for fatigue and effort. Commercial apps exist, but are paywalled or limited in scope. This project is an investigation into building a free, open alternative — starting from raw video and arriving at per-rep velocity estimates using pose detection, signal smoothing, and automated phase detection. I wanted something fast, free, and mine. So I built it.
Simplifying the Problem: Start With the Deadlift
The three powerlifting movements present different challenges for computer vision. In a squat, the lifter's wrists can be occluded by the barbell plates or rack posts. In a bench press, the lifter is horizontal and their head may be out of frame. But in a deadlift, the athlete is fully upright and visible throughout the lift. The barbell path is nearly vertical. The wrists stay in view.
Starting with the deadlift was a deliberate choice to simplify the problem. A clean baseline on the easiest movement is more useful than a fragile solution stretched across all three. Once the deadlift pipeline was working, generalizing would reveal exactly which assumptions broke down for the other lifts. This turned out to be exactly right.

Finding the Right Detector

Rather than tracking the barbell directly, the approach shifted to tracking the lifter's wrists. YOLO Pose is a variant of YOLO trained to detect human keypoints — joints including wrists, elbows, shoulders, hips, knees, and ankles — from a single frame. It produces a keypoint confidence score per joint per frame, so the pipeline degrades gracefully under occlusion: it flags rather than guesses.
YOLO Pose tracks 17 body keypoints per frame. Wrists grip the bar and move with it near-exactly — a stable proxy without needing to detect the barbell itself. Testing across model sizes showed that stability improved significantly at larger sizes; since this runs on offline video, inference speed is no constraint.
▶What I tried first
Taming the Signal
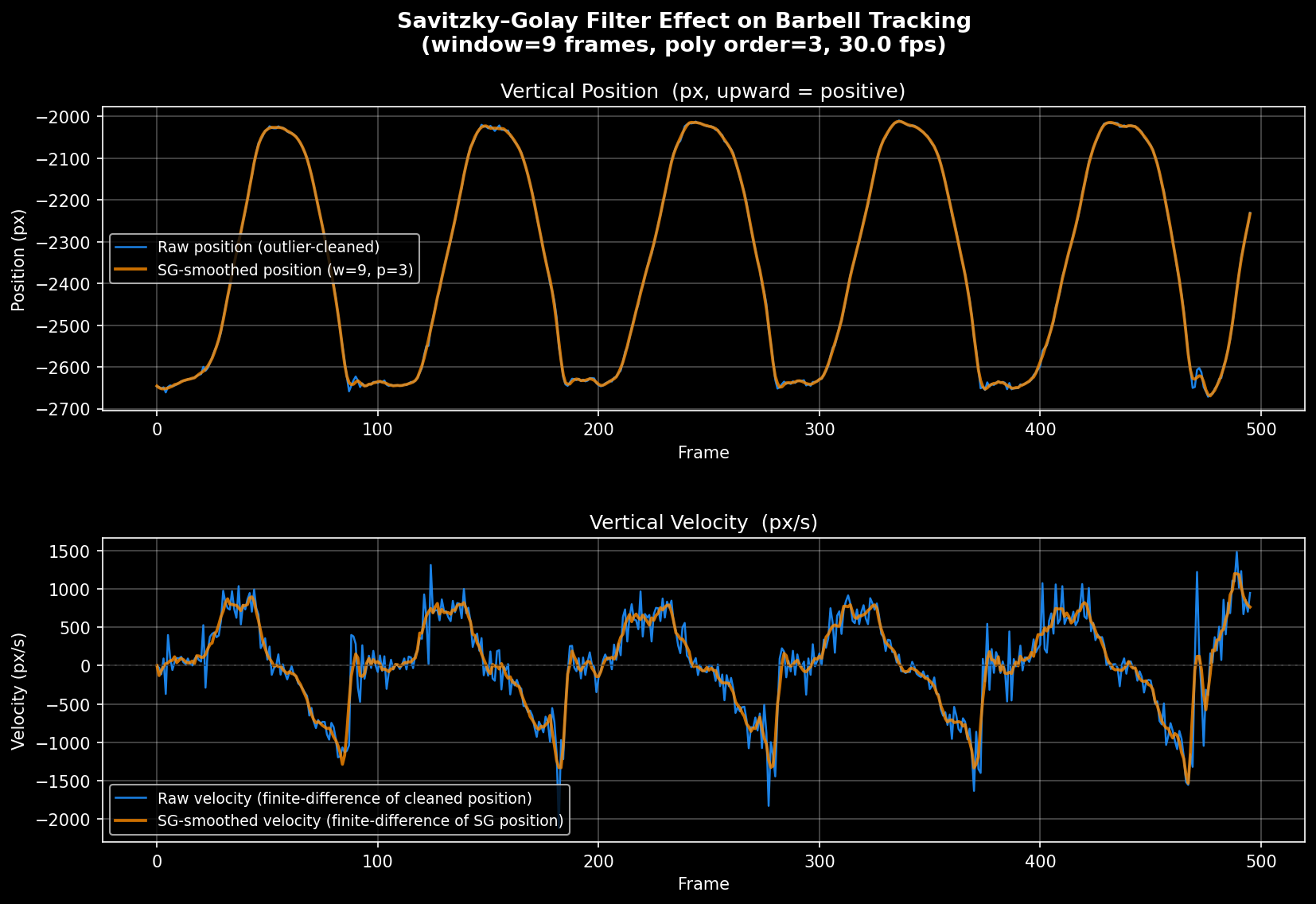
Raw keypoint positions jitter frame-to-frame — noise that gets amplified when differentiated into velocity. Velocity is the finite difference of position: how far the wrist moved between frames, divided by the time between them. Any noise in position becomes a spike in velocity.
The Savitzky-Golay filter works by fitting a polynomial to a sliding window of data points, then using the fitted value at the center as the smoothed output. Think of it as a local curve-fitter rather than a blunt averager. The key advantage over a simple moving average is that it preserves peak shape. A moving average flattens peaks by averaging them with their neighbors — systematically underestimating peak bar speed, exactly the metric VBT depends on. Savitzky-Golay avoids this.
Isolating the Concentric Phase
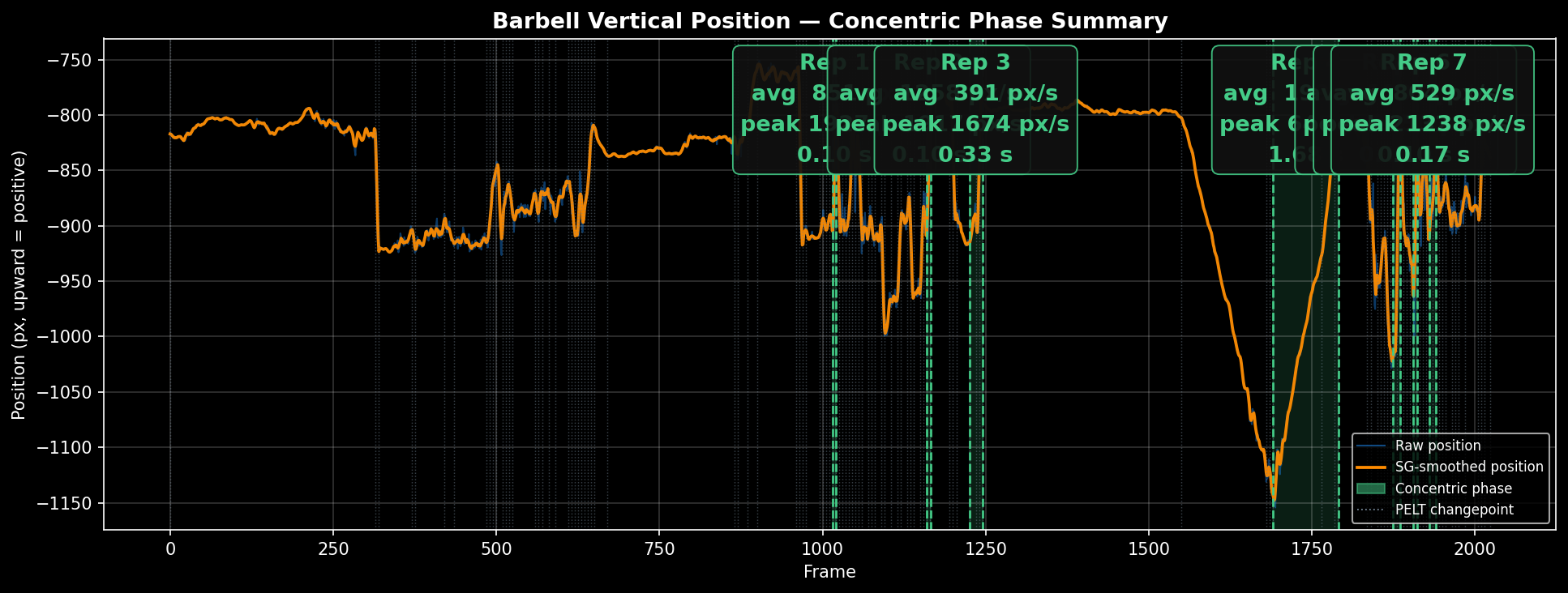
A deadlift session video contains more than just the upward pulls — there are setup movements, pauses at lockout, the descent, and idle time between sets. For VBT, only the concentric phase matters: the upward portion of each rep where the bar is actively lifted.
PELT was applied not to the raw position signal but to the velocity signal — the first difference of smoothed position. Applied to position, a sustained upward movement looks like many small constant-mean pieces, so PELT over-segments. On velocity, a clean concentric phase is a single near-zero-mean segment, making it one coherent piece to find.
Three post-processing steps follow the raw PELT output: merge adjacent candidates above velocity threshold, extend phase boundaries while velocity supports it, and reject candidates below 50% of median candidate velocity.
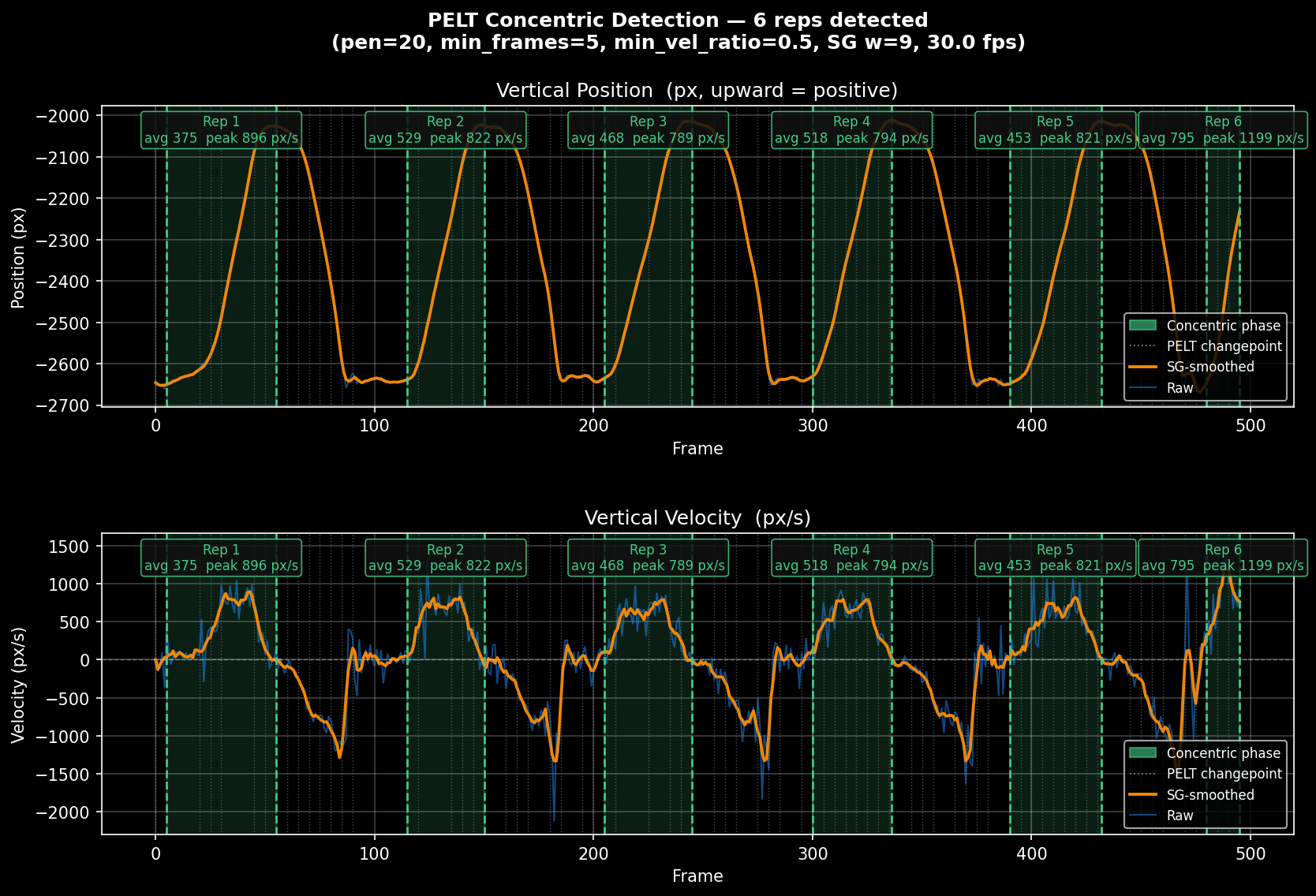
Each shaded region is one rep's concentric phase — automatically detected, no manual labelling.
▶Why not scipy peak-trough detection?
The obvious approach was scipy's peak-trough detection — find local maxima and minima in the position signal, infer lifting phases from the intervals between them. It works in principle, but proved sensitive to noise in the signal and required careful parameter tuning tied to signal properties that shift between sessions. PELT on the velocity signal is more robust: it finds statistically distinct constant-mean pieces rather than relying on absolute extrema.
▶How PELT changepoint detection works
PELT (Pruned Exact Linear Time) segments a signal into statistically distinct constant-mean pieces. A penalty term controls how many segments are allowed — lower penalty allows more segments; higher forces fewer, coarser divisions.
Applied to position, a single upward pull looks like many small constant-mean pieces — PELT over-segments. Applied to velocity, a clean concentric phase is a single near-zero-mean segment (bar moving at roughly steady speed) — exactly one piece for PELT to find.
Extracting Per-Rep Velocity
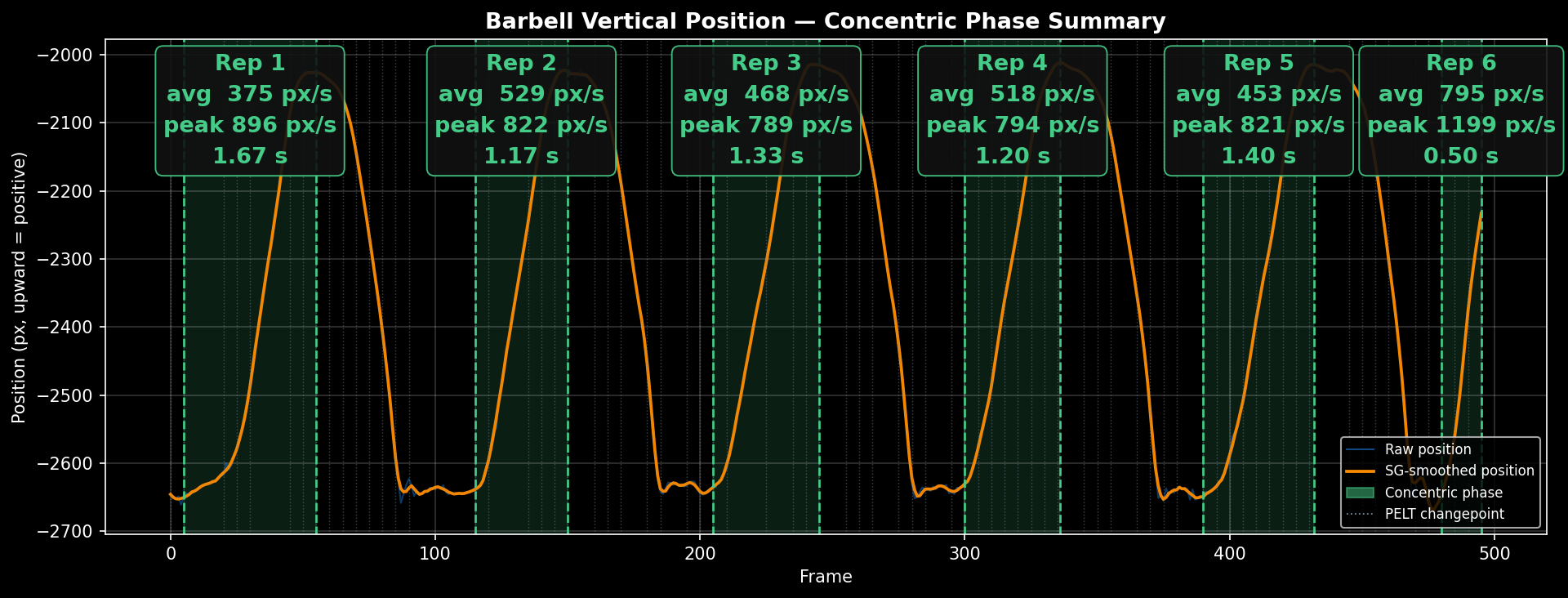
The pipeline produces velocity in pixels per second — how fast the wrist, and by proxy the barbell, is moving in the frame. This is not directly comparable across different lifters, camera distances, or angles. But for a single lifter using a consistent setup, it is a perfectly valid relative metric: Rep A was faster than Rep B, Set 3 was slower than Set 1. That is the signal VBT cares about.
For now, rep time in seconds also serves as a sufficient proxy. If the lift setup is held constant, rep time correlates directly with velocity — with the caveat that variations with different ranges of motion (sumo vs. conventional deadlift) are not comparable at equal bar speeds.
▶The m/s calibration problem
Converting px/sec to meters per second requires knowing how many pixels correspond to a real-world meter in the frame — the camera's scale factor. This varies with camera distance, focal length, and lens distortion.
The clean solution is to film with a calibration reference: a checkerboard pattern of known dimensions placed in the frame. Standard practice in camera calibration — it works, but adds friction to every recording session.
Without calibration, a rougher proxy is the lifter's known range of motion. If the lifter knows their pull is 60 cm and the bar travels 480 pixels, the scale factor follows. But this requires measuring or estimating range of motion per session, and doesn't account for lens distortion. This remains an open problem.
Results
Deadlift
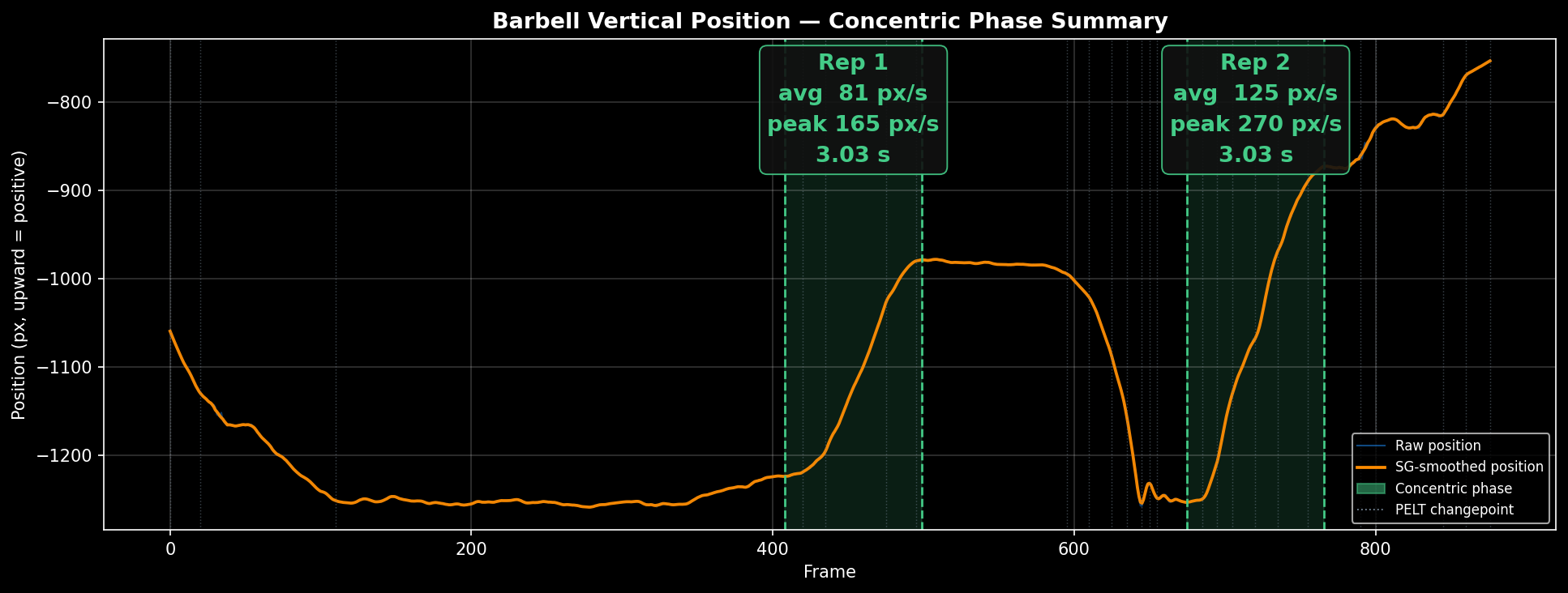
Rep 2 is detected but corresponds to the lifter stepping away from the bar, not a working set rep — a false positive from the phase detection step.
The deadlift is the right baseline: the lifter is fully upright and visible throughout the lift, the barbell path is nearly vertical, and the wrists stay in view from setup to lockout. There are no occlusion events and no ambiguity about which phase is the concentric pull.
The pipeline is reliable on this movement. YOLO Pose tracks the wrist keypoints stably across frames, Savitzky-Golay smoothing preserves the velocity peak without flattening it, and PELT cleanly segments each rep's concentric phase with minimal post-processing intervention.

Squat
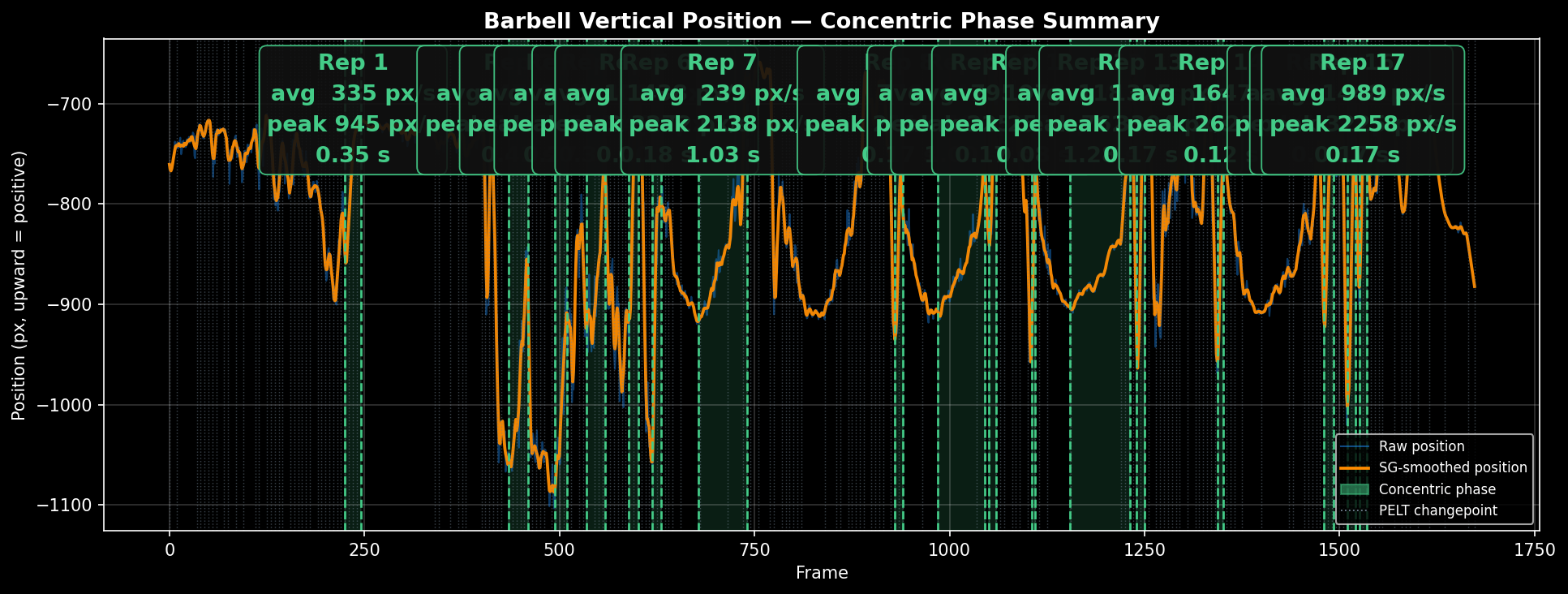
The squat pipeline worked, with one important constraint: the lifter's wrists must remain in frame throughout the lift. At the bottom of a squat, the wrists can be occluded by the barbell plates or rack posts depending on camera angle. When that happens, the YOLO Pose model loses confidence on the wrist keypoints, and tracking falters for those frames.
The practical fix is a camera placement that keeps the wrists visible throughout — typically slightly elevated and to the side. This is a reasonable constraint for a controlled training setup.

Bench press
The bench press exposed a deeper problem. When a lifter is lying down on the bench, the standard side-on camera angle means the lifter's head is usually not in frame. This matters more than it initially seems.
YOLO Pose is a top-down detector: it first finds a bounding box around a person, then runs keypoint estimation within that box. The person detector is trained predominantly on upright or near-upright humans. A lifter lying horizontal, seen from the side, with no visible head, is substantially out-of-distribution for the detector. The failure happens before keypoint extraction even runs — the person bounding box is not found reliably, so no keypoints are extracted.
The fix was a high camera angle: positioning the camera overhead (or at a steep diagonal) so that the lifter's head and wrists are both visible throughout the lift. This brings the body orientation back into distribution for the person detector.
